
# はじめに
Misskeyのサーバー探しで困ったことはありませんか?公式のリストが止まっていたり、実態のわからないサーバーが混ざっていたり。そんな状況に業を煮やし、最新の状況を自動で反映し続けるサーバーリストを作成しました。

本当は今年のMisskey Advent Calendarのネタにしようかとも思っていたのですが、どうせ技術的な記事は他の方々がたくさん書かれているだろうし、何より当時のUIはちょっと見せびらかすには残念な出来だったので見送っていました。 そんなわけで、諸々がいい感じに仕上がってきたので、少し遅れての登場です。
私が (Unofficial) Misskey Server List を作成しようと思い立った直接のきっかけは、Misskey公式のMisskeyHubに掲載されていたインスタンス一覧が、長期メンテナンスに入ったまま復旧しなくなってしまったことでした。 開発者からは「ユーザーの混乱を避けるため」といった趣旨の説明がなされていましたが、その裏にある実情は十中八九、Misskeyの派生プロジェクトであるCherryPickによる実装変更が引き金でしょう。
現行のCherryPickは、User-AgentにJoinMisskeyの文字列を含むリクエストに対してのみ、メタデータ上で自身をMisskeyであると偽装して返すという、極めて行儀の悪い実装を行っています。JoinMisskeyとは、aqz氏が個人でメンテナンスを行っているインスタンス一覧のデータソースであり、MisskeyHubも内部的にこれを利用していました。その結果、本来掲載されるべきではないCherryPickのインスタンスが、Misskeyの顔をして公式リストに混入してしまう事態が発生していました。
私自身、新しいインスタンスが生えていないか定期的に見に行っていたため、この信頼できない状況には困っていました。 「ならば、自分で納得できるクリーンなリストを作ろう」というのが、開発の出発点です。
# 本物を識別する
「Misskeyのインスタンスだけを集めたい。」言葉にするのは簡単ですが、いざ実装しようとすると、すぐに多様性とスプーフィングの壁にぶち当たります。ActivityPubのおかげで、MastodonもFirefishも、そして悪意ある偽装サーバーも、外向きには同じような顔をして通信してくるからです。加えて、フォーク文化が盛んであり、独自機能を追加した派生版も無数に存在します。そんな混沌としたFediverseの中から、どうやって本物と偽物を分別しているのかと言えば、幸いなことにCherryPickはJoinMisskeyに対してのみMisskeyを名乗るような仕草をしていたので、これを逆手に取りました。
私が実装した検出機構では、単にリクエストを投げるだけでなく、意図的に異なるUAでリクエストを投げています。まず通常のブラウザなどを模したUAと、JoinMisskeyを模したUAの二種類を用意し、その双方から対象サーバーの/api/metaおよび/nodeinfo/[2.0|2.1]にリクエストを投げます。もし、ここで返ってきたJSONレスポンスの内容、特にsoftwareNameやバージョン情報に矛盾がある場合、あるいは相手によって応答を変えるような挙動が見られた場合は、その時点で信頼できないノードとして即座に弾く仕組みにしました。
また、なるべく全ての工程を自動化したかったので、Misskey以外のソフトウェアを機械的に判定し、排除する機構が必要でした。対象のホストがMisskeyを名乗っており、JoinMisskeyが公開しているignorehosts.ymlに含まれていないことは最低条件ですが、それだけでは足りません。正常なレスポンスを返すかどうかの監視に加え、レポジトリ情報の検証も徹底しています。具体的には、APIで返却されるレポジトリURLが公式のものなのか、あるいは信頼できないフォークを含まないかを厳密にチェックします。
中にはType-4nyのように過度な独自修正が加えられて独自のブランディングを行っていてもなお、nodeinfo上ではMisskeyを自称するようなフォークも存在します。そういったものを判定するため、データベース上に保持した除外リストや、既知のレポジトリパターン判定ロジックを用いて検知を行っています。このフィルタリングロジックは適宜更新し、常に概ね純粋なMisskeyを提供しているサーバーのみを抽出できるよう調整をしています。
中規模以上のサーバーだいたい何かしらのカスタマイズを施したMisskeyを利用しているのもあって、結局のところ「どの程度までをMisskeyと見なすか」は難しいラインではあります。しかし、そこに明瞭な指標もないので、取り敢えずは私の主観とコード上のロジックで決定しています。「これこそが公平な判定だ!」といういい感じのアイデアがある方がいれば、GitHubにPRを投げてくれれば採用するかもしれません。
# 連合探索
静的なリストではなく、各インスタンスの現状をリアルタイムに反映するため、いくつかの定期タスクを実装しています。
まずupdateタスクが6時間おきに実行され、登録済みのインスタンスを検証します。ユーザー数やノート数、登録開放状況といったメタデータを最新の状態に更新し、応答がないサーバーや410を返すサーバーはリストから除外します。
そして、新規開拓を行うのがdiscoveryタスクです。既存のリストの中でis_alive=true状態のMisskeyインスタンスをランダムに抽出し、そのサーバーが持つ連合先インスタンス一覧を取得します。そこに含まれるFQDNが未登録であれば、検証プロセスへ回します。
ActivityPubの特性上、稼働しているサーバーは高い確率で他のサーバーと連合しています。
つまり、既知のサーバーを起点にネットワークを辿ることで、主要なリレーやリストに登録されていない小規模な個人サーバーであっても自動的に検出が可能になります。これにより、手動登録に頼らずともある程度網羅的なリストを作成できるエコシステムを構築しました。
# アーキテクチャ
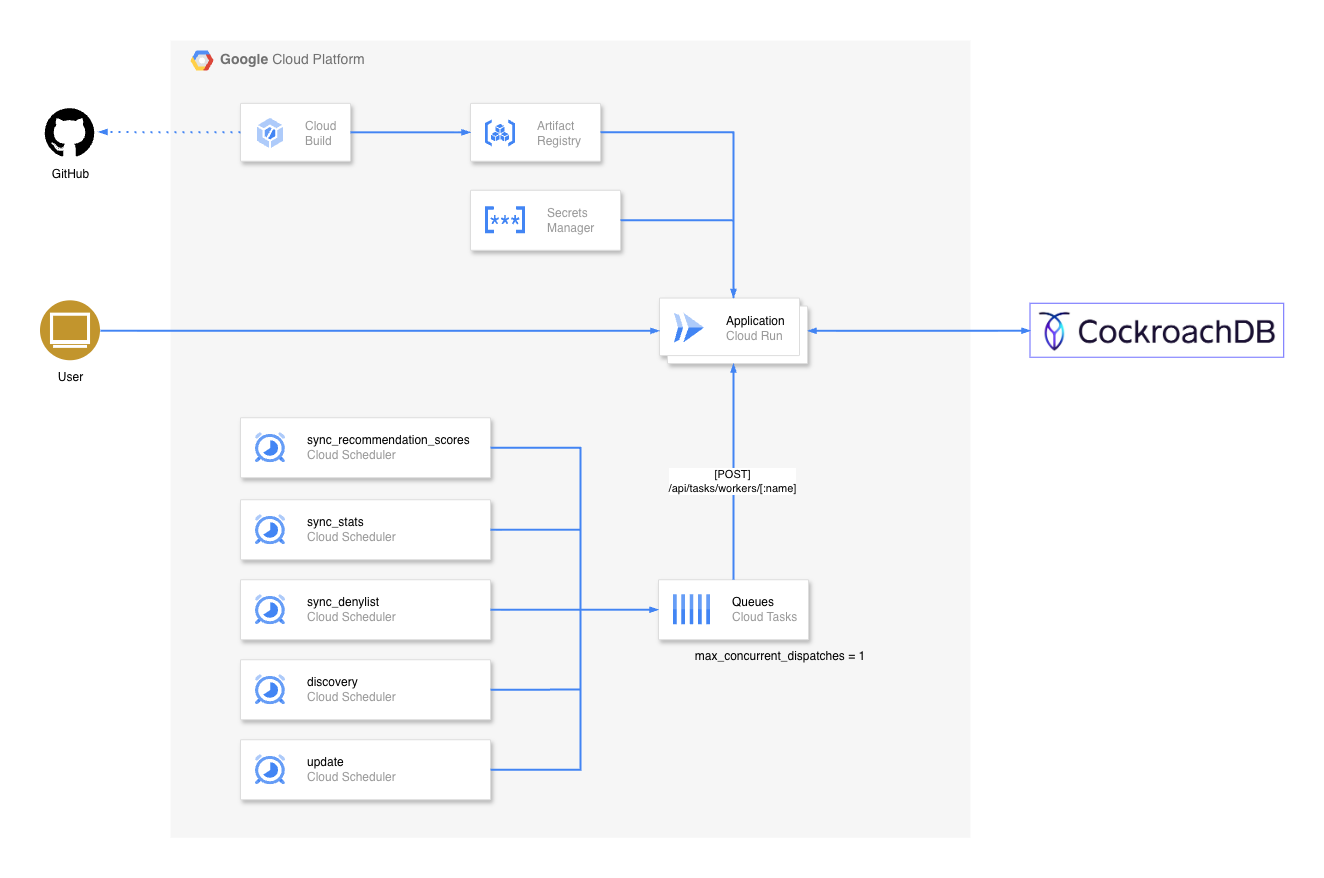
システムの構成についてですが、当初はCloudflare Workers / D1 / Queuesを中心に、APIだけを提供するつもりで開発を進めていました。しかしながら、数千件に及ぶ大量の連合情報を数時間に1度収集・解析する都合上、WorkersのCPU Time Limitに引っかかり、当然耐えられませんでした。特にJSONのパースやバリデーションといったCPUインテンシブな処理が重なり、タイムアウトが頻発しました。その致命的な問題に気付いたのは、コードを書き始め、実装の半分以上が完成してからでした。
どうせ構成を見直すなら、ついでにフロントも付けて目に見える形で多くの人に使って貰えたらなと思い立ったのもこのタイミングです。ここで技術選定を根本からやり直し、フレームワークにはNuxt4を採用、データベースにはCockroachDBを使用してアプリケーションを再構築しました。インフラ基盤はGoogle Cloud Platformで統一し、Cloud Run / Cloud Build / Cloud Scheduler / Cloud Tasks / Secrets Managerで構成しています。
この構想から設計、実装、そしてデプロイに至るまでの全ての工程は、丸2日程度で行いました。
全体的なアーキテクチャのイメージとしては、Cloud Schedulerが定期的にトリガーを引き、Cloud Tasksがジョブを管理し、Cloud Run上のアプリケーションがCockroachDBと連携しながら外部のMisskeyインスタンス群やGitHub APIを巡回する形になります。
また、Cloud Runをasia-northeast1を含む特定のリージョンで利用している際、Custom Domain Mappings を利用するとレイテンシが顕著に上昇する既知の問題がありました。これに対し Cloud Load Balancingを利用したルーティングと比較検証を行いましたが、結果として40ms 程度の違いしか見られなかったため、LB の維持コストとの兼ね合いでそのままマッピングを行っています。検索クエリを叩かなければレスポンスはキャッシュされる前提で実装をしているおかげか、ユーザー体験に顕著な差は現れませんでした。
これらの基盤は全て Terraform でコード化して管理しています。
会社でも普段はAWS基盤ばかり利用していますが、GCPの開発体験はAWSのそれと比べてだいぶ分かりやすく、直感的であるという印象を覚えます。無料枠も太っ腹なので嫌いじゃないです。
# 非同期分散処理
タスク実行基盤として、当初はCloud SchedulerからCloud Runのエンドポイントを直接呼び出していましたが、処理量の増加に伴いタイムアウトで処理が中断されるリスクが顕在化し、Cloud Tasksを導入しました
現在のアーキテクチャでは、Cloud Schedulerはタスクの実行をエンキューする軽量な処理のみを行います。具体的には、Cloud Schedulerが/api/tasks/:nameを叩くと、アプリケーションは処理を直接実行せず、Google Cloud Tasksのキューにタスクを積みます。
ここの重要な点として、キューのmax_concurrent_dispatches(最大同時実行数)を1に制限しています。これは、外部インスタンスへの過度なリクエストを防ぐ行儀の良さの担保と、自身のデータベース接続数の枯渇を防ぐためです。タスク名にタイムスタンプを含めて重複実行を排除し、失敗時にはCloud Tasksのリトライポリシーによって自動的に再試行される堅牢な設計としています。
また、Cloud TasksからCloud RunへのリクエストにはOIDCトークンが付与されており、Cloud Run側でリクエストが正当な権限を持ったサービスアカウントからのものであるかを厳格に検証しています。つまり、/tasks/workers/[:name]エンドポイントはインターネットに公開されていますが、実質的には内部からしか叩けない設計となっています。人間が手動でキックするためのエンドポイントには独自のBearerトークン制限をかけ、システムからの自動実行にはIAM認証を用いるいい感じのセキュリティを実現しました。
# 言語の判定
実装において最もかつ苦労したのはインスタンスの主要言語判定です。ユーザーが新しいサーバーを探す際、「そこで何語が話されているか」はサーバーのテーマと同じくらい重めな条件になります。しかし、Misskeyの仕様上、言語設定は必須ではなく、説明文も英語と日本語が混在している文章や極端に短い文章で構成されているといったケースが多々あります。APIから得られる情報だけでは、そのサーバーが実際にどの言語圏のコミュニティなのかを正確に断定することが困難でした。
既存の言語判定ライブラリもいくつか試しましたが、短文やノイズの多いテキストに対してはどれも単体では実用に耐えうる精度が出ませんでした。そこで、複数のロジックを組み合わせた合議制アルゴリズムを実装して解決することにしました。
判定プロセスは三段階に分かれており、第一段階として、テキスト内の文字コードの範囲を走査するヒューリスティック判定を行います。日本語や中国語、韓国語のように特徴的な文字種が含まれていれば、重い処理を回すまでもなく高速に言語を確定できます。ここで判別がつかない場合は第二段階として、特性の異なる3つの言語判定ライブラリに判定を委ね、多数決投票を行います。アルゴリズムの異なるライブラリに投票をさせることで、個々の誤判定を相互に補完させる狙いです。
さらに、それでも結果が割れて怪しい場合は、実際にそのサーバーのLTLから直近の投稿20件を取得し、実データのサンプリングに基づいて解析を行っています。
最近だとLLMのAPIもだいぶ安くて、Geminiあたりを使ってもよかったのですが、自動で収集と判定を延々と繰り返している、かつMisskeyを利用する全てのインスタンス数が把握できない以上、ランニングコストの試算ができなかったため無謀すぎてやめました。もし対象が小規模かつ試算ができる状態であれば、実装コスト諸々との天秤にかけて利用していたと思います。
また、どれだけ収集能力が高くても、ノイズだらけでは意味がありません。そのため、除外リストの運用には細心の注意を払っています。ベースとなるのはJoinMisskeyが公開しているignorehosts.ymlですが、これはあくまで最低ラインです。当リストでは、これに加えて独自の検疫プロセスを導入しています。例えば、一度は正常にMisskeyと判定されたサーバーであっても、その後の定期観測でソフトウェア名の偽装や、Misskey以外の実装への変更などといった不審な変更が見られた場合、自動的にシステム側の除外テーブルに追加され、リストから排除されます。また、Misskey以外のAP実装が誤って検出された場合も、同様にフィルタリングされます。このプロセスは完全に自動化されており、私の主観が入り込む余地を排除しています。
# 透明性がどうのこうの
幸か不幸か、インターネット人間として長年活動している中で、私を嫌う方々に粘着されてしまっていて、こういうものを作ると必ずいちゃもんを付けられることが懸念されました。具体的には、「私の気に食わないサーバーを意図的に排除している」だとか、「公平性に欠く基準で恣意的にレコメンドしている」なんかがそうですね。
まぁ、個人運営のリストに対する主張としては妥当だと思うのですが、これに関して言えば私に限らず公式だろうと似たり寄ったりだろうと思うわけです。それにしても、こういうことをイチイチ言われるのも気分がいいものではありません。
こうした懸念を払拭するため、私は全ての情報を公開する方針をとりました。ソースコードはGitHub上にAGPL-3.0ライセンスのもと公開しており、収集した統計データ、除外リスト、そしてその除外理由に至るまで、全てAPIで取得可能です。
特にRecommendedスコアの算出ロジックについても、コード内のcalculateRecommendationScore関数を見ていただければ分かる通り、完全に数式です。ユーザー数や投稿数といった規模感に加え、GitHub Releasesから取得した最新バージョンに対する追随度や、活動率を係数として掛け合わせ、機械的にスコアを弾き出しています。たとえば、バージョンが古いサーバーはセキュリティリスクと見なし、指数関数的にスコアを減衰させる処理を入れています。そこに私の主観やお気持ちが入る余地は当然1ミリもありません。
実際、この懸念は杞憂ではなくて、公開直後にある方から直々に文句を言われてしまいました。こういうの言ってくる人って、自身の主張に妥当性があるかどうかすら考えないんですかね。コードも公開データも見ずに、イメージだけでいちゃもんをつけて来るのはかなり無理があります。文句があるならGitHubでIssueでも建ててもらえば、こちらとしても対等な議論として対応できるので幾分建設的だとは思うのですが、残念ながら彼女にその考えはなかったようです。
# さいごに
そんなわけで、年の瀬ギリギリの滑り込み記事でした。
元々は自分が不便だからという理由だけで作ったツールですが、公開してみると予想以上の反響があり、私としてはうれしい限りです。非中央集権の海は広大で、自由で、そして少しだけ不親切です。そんな中で、結果として誰かの役に立てたのなら、それはとても嬉しいことだと思います。
収集したデータはWebで見れるだけじゃなく、登録不要のAPIとして全開放しています。Botを作るもよし、統計を取ってニヤニヤするもよし。私のお財布が吹き飛ばない程度に、自由に叩き倒してください。ドキュメントも一応用意してあるので、バグや要望があればGitHubまで。PRはいつでも歓迎します。
それでは、よいお年を。