
Misskey向け(匿名)質問箱「Mewk」を作った
- 投稿した日
- 2026/03/26
- 読了まで
- 28.41分で読み終われます (17,043文字)


リリースから1ヶ月少々が経ち、現時点で約2,000ユーザ、7,000件弱の質問が投稿されています。ありがたいことですね。
# なんでつくったの
Misskeyには既存の匿名質問箱サービスがいくつか存在します。
そんな中、何故わざわざ新しく作ったのか。
正直に言うと、既存のサービスに満足できなかったからです。
Misskeyは分散型のSNSであり、無数のインスタンスが独立して運営されています。しかし、質問箱となると、インスタンスを問わずに利用できる選択肢が限られていました。特定のインスタンス向けに提供されているサービスはありましたが、それらはそのインスタンスのユーザのために作られたものであり、他のインスタンスのユーザが使えるものではありません。Misskeyのエコシステム全体を見渡した時に、誰でも使える汎用的な質問箱が不足しているという状況がありました。
インスタンスを問わず利用できるものもいくつか存在しましたが、正直なところ常用するには厳しいものがありました。OGP画像の生成に対応していないため、質問や回答をSNS上で共有した際にリッチなプレビューが表示されず、せっかくの回答が素っ気ないリンクにしかなりません。UIもお世辞にも洗練されているとは言えず、全体的に作り込みの甘さが目立ちました。使っていて「もう少しなんとかならないのか」という思いが拭えませんでした。
既存ソフトウェアに文句を言うだけなら簡単です。しかし、他人が作ったものにケチをつけるくらいなら、自分が納得できるものを自分で作った方が建設的です。
どうせ作るなら、MFMを完全にサポートし、ユーザがカスタマイズできる機能を充実させ、リッチなUIでどのインスタンスからでも利用できる質問箱を作ろう。そう思って開発を始めました。
もう一つ、非公式Misskeyサーバリストを作った時に感じた、自分が作ったものを誰かに使ってもらえる体験をもう一度味わいたいという気持ちもありました。承認欲求と言ってしまえばそれまでですが、個人開発のモチベーションなんてみんなそんなものです。
# 構成
Mewkのアーキテクチャは大体以下の通りです。
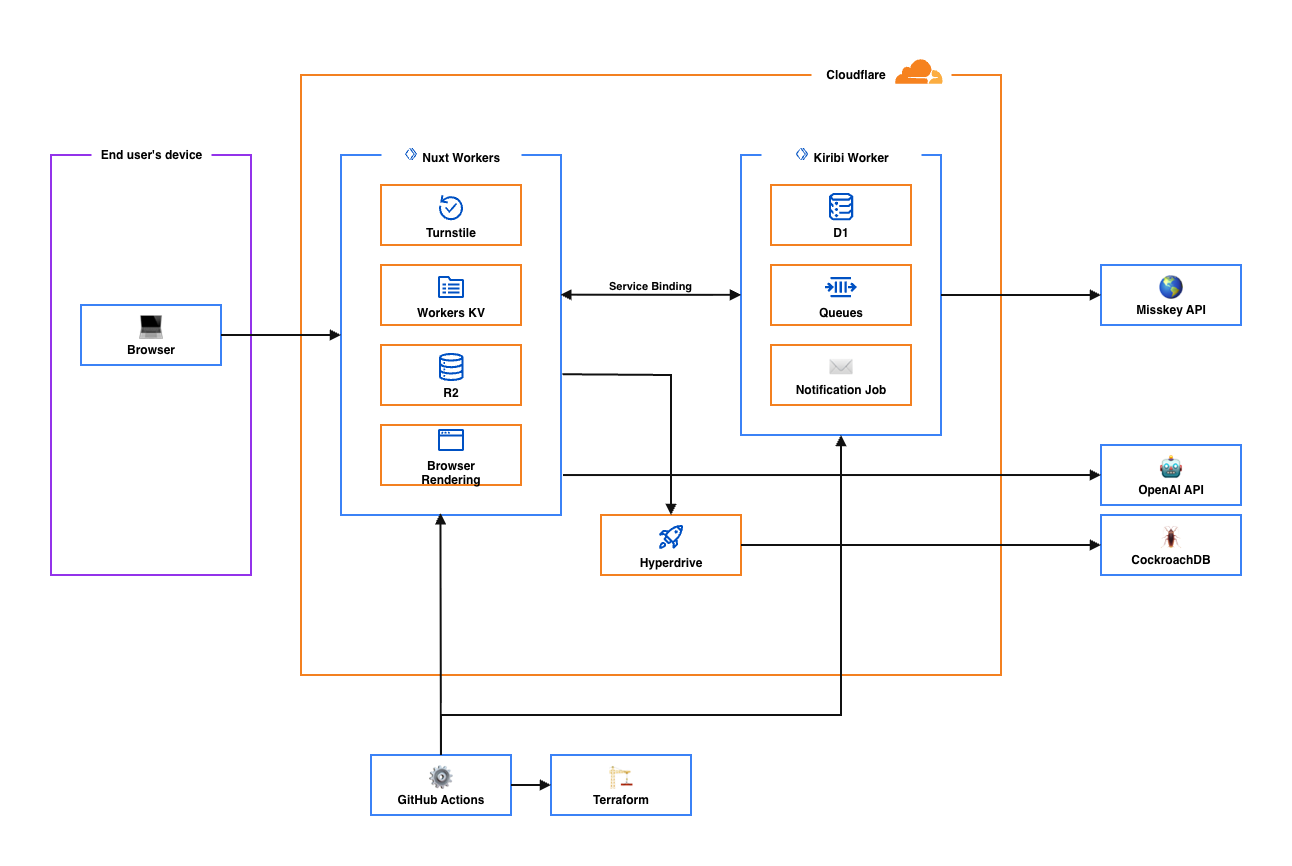
フロントエンドとバックエンドはNuxt 4で統一し、Cloudflare Workers上にデプロイしています。
データベースにはCockroachDBを採用していますが、PostgreSQL系のDBは総じてコネクション確立のコストが重く、リクエストのたびに新規接続を張る環境ではそのオーバーヘッドが顕著になります。そのため、Hyperdriveを経由して接続プーリングを行い、コネクションの使い回しによって応答速度を確保しています。
OGP画像の保存にR2、キャッシュやレートリミットにKV、非同期ジョブの処理には独立したKiribi Queue Workerを使い、インフラ管理はTerraform、デプロイはGitHub Actionsが担っています。
以前、非公式Misskeyサーバリストを作った際はGCPのCloud Runで動かしていましたが、今回はCloudflareに全振りしました。
理由は単純で、エッジコンピューティングの恩恵をフルに受けたかったことと、ずば抜けて安価であること、Cloudflareのエコシステムが以前に比べてかなり成熟してきたことが大きいです。
CockroachDBだけは外部ですが、Hyperdriveの接続プーリングのおかげで、エッジからDBへのレイテンシは実用上の問題にはなっていません。
# リソース管理
Cloudflareのリソース管理には、例によってTerraformを使っています。
KV Namespace、R2、Hyperdrive、D1、Queue、Workers Script、Custom Domain。これらの初期構築を全てIaCで管理し、stg/prodの環境分離もTerraformのworkspaceで行っています。
人の温もりが介在するようなインフラなんてとんでもなく恐ろしいですからね。
ところが、Workers Scriptのデプロイに関しては、Terraformだけで完結させることができません。Cloudflare APIに起因する厄介な問題があるためです。
resource "cloudflare_workers_script" "app" {
# 初回作成のみ Terraform が担当
content = "export default { fetch() { return new Response('Run wrangler deploy to update') } }"
bindings = [
{ name = "HYPERDRIVE", type = "hyperdrive", id = cloudflare_hyperdrive_config.db.id },
{ name = "R2_BUCKET", type = "r2_bucket", bucket_name = var.r2_bucket_name },
{ name = "BROWSER", type = "browser" },
{ name = "KV_CACHE", type = "kv_namespace", namespace_id = cloudflare_workers_kv_namespace.cache.id },
{ name = "KIRIBI", type = "service", service = cloudflare_workers_script.kiribi.script_name },
# ... シークレット等
]
lifecycle {
ignore_changes = all
}
}Cloudflare APIは、Workers ScriptリソースをGETした際にcontentフィールドを返しません。そのため、Terraform planを実行するとstateのcontentがnullになります。この状態で他の属性(bindingの追加等)を変更しようとすると、PUTリクエストにnullのcontentが含まれてしまい、syntax errorで死んでしまいます。
この問題を回避するため、Terraformにはリソースの初回作成とbindingの定義だけを担当させ、lifecycle { ignore_changes = all }で以降の変更を完全に無視させています。実際のコードデプロイはCDパイプラインからwrangler deployで行い、bindingの実態はwrangler.toml(Terraform outputから自動生成)で管理するという構成です。
一見すると冗長に見えるかもしれませんが、リソースの作成・削除はTerraformのplan/applyで安全に管理しつつ、頻繁に更新されるWorkerのコードはWranglerに任せるという棲み分けは、運用上かなり快適です。新しいbindingを追加する際も、Terraformでリソースを作成してoutputを更新し、wrangler deployで反映するだけなので、手順に迷うこともありません。
# Prisma on Cloudflare Workersの苦しみ
MewkではORMにPrismaを採用しています。
Prisma自体はCloudflare Workersランタイムに対応しており、WASMベースのクエリエンジンを使って動作する仕組みになっています。ところが、Nitro(Nuxtのサーバエンジン)がバンドルを行う際に、Prismaが生成したコード内の.wasmインポートパスが壊れるという既知の問題がありました。

Nitroのバンドラがソースツリー上の絶対パスをそのままバンドル出力に持ち込んでしまい、デプロイ先のCloudflare Workers環境では当然そのパスが存在しないため、WASMの読み込みに失敗しているようです。
正直、この問題にぶつかった時はかなり萎えました。ORMの選択を間違えたかと一瞬後悔しましたが、Prisma以外を使いたくはなかったので、力技で解決する道を選びました。
そこで、ビルド後の成果物を直接書き換えるスクリプトを用意しています。
const OUTPUT_SERVER = resolve('.output', 'server');
const WASM_SRC = resolve('generated', 'prisma', 'internal', 'query_compiler_fast_bg.wasm');
const WASM_DEST = join(OUTPUT_SERVER, 'chunks', 'query_compiler_fast_bg.wasm');
// WASMファイルをビルド出力にコピー
copyFileSync(WASM_SRC, WASM_DEST);
// Nitro出力内のWASMパスを正しい相対パスに修正
const fixed = content.replace(
/["'][^"']*generated\/prisma\/internal\/query_compiler_fast_bg\.wasm(?:\?module)?["']/g,
'"../query_compiler_fast_bg.wasm?module"',
);
// Wranglerのmodule collectorが?module付きパスでENOENTになるため正規化
const withoutModuleSuffix = fixed.replace(
/query_compiler_fast_bg\.wasm\?module/g,
'query_compiler_fast_bg.wasm',
);
// Wranglerの警告ノイズを抑制
const withoutNodeProcessImport = fixed.replace(
/import\s*["']node:process["'];?/g,
'',
);やっていることを整理すると、まずPrismaが生成したWASMバイナリをビルド出力ディレクトリにコピーし、Nitroが出力した.mjsファイル群を走査して、壊れた絶対パスを正しい相対パスに書き換えます。さらに、Wranglerのmodule collectorが?moduleサフィックス付きのパスをそのままopen()してENOENTになることがあるため、サフィックスを除去して正規化します。最後に、Wrangler側でsideEffects=false判定により無視されるnode:processのbare importを事前に除去して、デプロイ時のwarnを抑えています。
実装としては全然綺麗じゃないですし、寧ろすごく汚いと思います。ビルド成果物を正規表現で書き換えるなんて、お世辞にも上品とは言えない力技です。
しかし、こんなのでも動いてしまいます。Prismaのバージョンが上がるたびにパスの形式が微妙に変わって壊れないか冷や冷やしていますが、今のところは安定して動いてくれています。Prisma側でこの問題が修正されるのを心待ちにしつつ、それまではこの暫定対応で凌ごうかと思っています。
他にいい感じの方法をご存じの方がいれば教えて頂けるとうれしいです。
# 非同期ジョブの処理
## Kiribi
非同期ジョブの処理にはKiribiを採用しています。
これは、Cloudflare QueuesベースのジョブワーカーフレームワークでD1でジョブの状態管理を行い、Cronトリガーで定期実行をスケジューリングできます。
リリース直後はCloudflare Queuesを素で使っていましたが、Queues単体ではメッセージの取りこぼしや重複配信が発生することがあり、at-least-onceの保証も万全ではありませんでした。KiribiはD1でジョブの状態を永続化しているため、Queues側で問題が起きてもジョブの追跡と再実行が可能であり、信頼性の面で大きな旨味があります。
サービスの性質上、非同期で処理したいタスクはいくつもあります。定期投稿の配信、Misskey通知の送信、アカウント削除の後処理。これらをメインのWorkerで同期的に処理してしまうと、レスポンスが悪化しますし、外部APIの障害に引きずられてサービス全体が不安定になりかねません。
特にMisskeyの場合、接続先はビックテックの安定した中央集権的なサーバではなく、個人が運営するインスタンスが大半を占めており、その多くが不安定です。サーバの応答速度もまちまちですし、メンテナンスで丸一日落ちていることも珍しくありません。さらに厄介なのが、まともなスコープ設計もできないくせにWAFの設定を雑に盛る管理者の存在です。/api/*のようなパスにまでmanaged challengeを課しているせいで、API呼び出しが容赦なく蹴られてしまいます。まともな設計すらできないようであれば、デフォルトのまま運用してほしいものですが、こういうインスタンスのせいで的外れな問い合わせがこちらに無限に届くのは本当につらい😭
少し話が逸れましたが、ともあれ、こういった不安定で理不尽な外部依存を同期的に抱えるのは、サービスの安定性にとって致命的です。
export default class extends Kiribi {
defaultMaxRetries = 20;
async scheduled() {
await this.enqueue('SCHEDULED_POST_DISPATCH', {}, {
retryDelay: { exponential: true, base: 2 },
});
await this.enqueue('PROCESS_ACCOUNT_DELETIONS', {}, {
retryDelay: { exponential: true, base: 2 },
});
await this.sweep();
}
}defaultMaxRetries = 20は一見やりすぎに見えるかもしれませんが、前述の通り、Misskeyサーバは個人運営のものも多く、メンテナンスで数時間から数日停止することは珍しくありません。指数的バックオフでリトライ間隔が指数的に伸びていくため、20回リトライしたところで相手サーバに過剰な負荷をかけることはおそらくありません。むしろ、粘り強くリトライすることで、サーバが復帰した際に確実にジョブを完了させることができます。
ユーザにとっては「通知が来なかった」「定期投稿が飛んだ」といった誰にでも目に見えて分かる不具合が不満になりそうなので、ここは粘っておくべきなのかなと考えます。
## JobとService binding
現在、Kiribiで処理しているジョブは4種類あります。
- SCHEDULED_POST_DISPATCH
定期投稿のdispatch。Cron triggerから毎時実行され、投稿待ちのユーザを検索して個別のSCHEDULED_POSTをenqueue
- SCHEDULED_POST
実際のMisskey投稿処理。Nuxtの内部向けAPIエンドポイントでDBバリデーションとトークンの解決を行い、Misskey APIを叩いてノートを作成
- MISSKEY_NOTIFICATION
各Misskeyインスタンスへ通知の送信
- PROCESS_ACCOUNT_DELETIONS
アカウント削除の非同期処理
これらのジョブを実行する上で特徴的なのが、Kiribi WorkerとNuxt間の通信です。
export class ScheduledPost extends MewkPerformer {
async perform(payload: { userId: string }) {
// NuxtでDB prep(バリデーション、トークン解決、テキスト構築)
const prepRes = await callMewkInternal<...>(
this.env, '/api/_internal/scheduled-post-prepare', payload
);
if (!prepRes.success) return;
// Misskey API呼び出し
const noteRes = await fetch(`https://${prepRes.domain}/api/notes/create`, { ... });
if (!noteRes.ok) {
// 失敗時: KV ロック解除
await callMewkInternal(this.env, '/api/_internal/scheduled-post-release', { ... });
throw new Error(`Misskey note create failed`);
}
// 成功記録
await callMewkInternal(this.env, '/api/_internal/scheduled-post-complete', payload);
}
}Kiribi WorkerはService BindingでNuxtのWorkersに接続し、X-Internal-Secretヘッダで認証を行っています。DB操作やトークンの暗号化・復号といったメインロジックは全てNuxt側の_internalエンドポイントに集約し、Kiribi側では外部API呼び出しだけを責務としています。
なお、ここで軽く触れているトークンの暗号化・復号についてですが、MewkではMiAuthで取得したユーザのアクセストークンを平文のままDBに保存することはしていません。
万が一DBの内容が流出するような事態が起きたとしても、ユーザのMisskeyアカウントが乗っ取られるという最悪のケースを防ぐため、トークンは全て環境変数に持たせたキーを利用してAES-256-GCMで暗号化した上で保存しています。

これらの処理を含め、Nuxt側にロジックを寄せた理由は明確で、DBアクセスや機密情報を扱う処理がKiribi Workerに漏れ出すことを防ぎたかったためです。
Prismaの依存をNuxtに閉じ込めることで、Kiribi Workerは純粋にHTTP呼び出しの組み合わせだけで構成されます。
先述のPrisma WASMパスの問題も含め、Prismaの面倒はNuxtだけが見ればいい。依存関係がシンプルになれば、それだけ楽になります。
# MFMを含むOGP画像の生成
OGP画像の生成は、Mewkの開発において最も試行錯誤した部分の一つです。結論から言えば、最終的にCloudflare Browser Renderingに落ち着いたのですが、そこに至るまでに2回の挫折を経ています。
## Satori
最初に検討したのはSatoriでした。Vercelが開発しているHTML/CSSからSVGを生成するライブラリで、v8でも動作し、動的なOGP画像を生成する用途では広く使われています。エッジで完結するのでそれなりのパフォーマンスが期待できますし、外部依存もない。理想的な選択に見えました。
しかし、PoCの段階で早々に断念しました。
Mewkは、MFMのレンダリングをマストな要件としています。
MFMはただの単純なMarkdown拡張構文ではなく、アニメーション、カスタム絵文字、回転、反転、虹色テキストなど、かなり独自の記法を含むマークアップです。これをmfm-jsでパースし、Vueコンポーネントとしてレンダリングするのがフロントエンド側の実装なのですが、SatoriはHTMLのサブセットしかサポートしておらず、MFMの多彩な装飾を再現することが根本的に困難でした。
CSSアニメーションは当然動きませんし、カスタム絵文字は外部画像として取得・埋め込みが必要で、MFM特有のネストされた装飾の組み合わせをSatoriのレイアウトエンジンで正確に再現するのは現実的ではありませんでした。
OGPは静止画なのでアニメーション自体は不要ですが、それでもMFMの見た目をある程度再現しようとすると、Satoriの表現力では足りませんでした。
## Playwright on Cloud Run
Satoriがダメなら、実際のブラウザでレンダリングしてスクリーンショットを撮るしかない。そこで次に試みたのが、GCPのCloud Run上でPlaywrightを動かす方法でした。
コンテナにChromiumを詰め込み、Playwrightでヘッドレスレンダリングを行い、スクリーンショットを撮影する。
これはちゃんと動きます。実際にPoCレベルでは問題なく動作しました。やったね。
しかし、いざ本番を見据えてコスト試算を行うと、頭を抱えることになりました。
ブラウザの起動にはそれなりのリソースが必要で、Cloud Runのインスタンスにブラウザを常駐させるとメモリ消費が馬鹿にならず、コールドスタートからの起動も遅い。
OGP画像の生成はユーザ登録時や質問投稿時に都度発生するため、スケールさせるとリソース消費が線形に増加します。勿論そんな金銭的余裕はありません。こんなものを多用していたら破産してしまいます。
加えて、処理速度にも難がありました。Cloud Runのコールドスタートを含めると、1枚のOGP画像生成に数秒から十数秒かかることもあり、UXとしても許容しがたいものでした。
## Cloudflare Browser Rendering
2回の挫折を経て、最終的に採用したのがCloudflare Browser Renderingです。Cloudflareが提供するヘッドレスブラウザ環境で、Puppeteerを使ったページのスクリーンショットを撮影できます。
Cloud Run + Playwrightとやっていることの本質は同じですが、決定的な違いはインフラ管理が不要であること、そして追加コストが(ほぼ)かからないことです。ブラウザの起動やリソース管理はCloudflare側がよしなにやってくれますし、レイテンシも低い。まさに求めていたものでした。
発想としてはシンプルで、OGPレンダリング専用のVueページを用意し、そのページをBrowser Renderingでスクリーンショットに撮る、というだけの話です。実際にブラウザでレンダリングするので、MFMの装飾もカスタム絵文字も、フロントエンドと全く同じ見た目で出力できます。
OGPレンダリング用のVueページはユーザーページ向けのものと、質問ページ向けのものを2種類を用意しています。ユーザのプロフィールカードと質問カードをそれぞれ1200x630のJPEGとしてキャプチャし、R2にアップロードしてDBにキーとBlurHashを記録します。
生成された画像は次回以降のリクエストではR2から直接配信されるため、Browser Renderingが毎回走ることはありません。画像の再生成が必要なタイミング(ユーザがプロフィールを更新した場合など)にのみ、非同期で再生成を行うようにしています。
## 循環レンダリング
ここで一つ、躓きました。
OGP画像の生成は、ユーザページや質問ページへのアクセス時にトリガーされます。具体的には、APIレスポンスにOGP画像キーが存在しない場合、waitUntil()を利用バックグラウンドで生成処理を走らせます。
const shouldRegenerateOgp = !skipOgpRegeneration && (!ogpImageKey || hasLegacyPngOgp);
if (shouldRegenerateOgp) {
const cfCtx = event.context.cloudflare.context;
const ogpPromise = generateOgp(...).catch(() => {});
if (cfCtx?.waitUntil) {
cfCtx.waitUntil(ogpPromise);
} else {
await ogpPromise;
}
}問題は、OGPレンダリング用ページもSSRで動作するため、内部的に同じAPIを叩くということです。何も対策しないと、OGP生成→レンダリングページアクセス→API呼び出し→OGP画像なし→OGP生成→…といった循環参照に陥ってしまいます(ました)。
これを防ぐため、OGPレンダリング用ページからのAPIリクエストにはskipOgpRegeneration=1というクエリパラメータを付与し、再生成をスキップさせています。地味ですが、これがないとBrowser Renderingのセッションを無限に食い潰してしまうので、割と致命的です。実際、開発中にこの対策を入れ忘れた状態でテストしてしまい、Browser Renderingのセッション数が一瞬で枯渇したことがあります。
リトライは最大3回、線形バックオフ付きです。Browser Renderingは稀にタイムアウトすることがあるため、リトライなしでは運用に耐えませんでした。
# モデレーション大変だよね
OGP画像の生成も手強かったですが、正直に告白しますと、開発期間の中で最も時間を食ったのは主要機能の実装ではなく、このモデレーション系の実装でした。
匿名質問箱というサービスの性質上、悪意のある投稿への対策は避けて通れません。匿名であるがゆえに、誹謗中傷やスパム、有害コンテンツの投稿は必ず発生します。「善意のユーザが大半だから大丈夫だろう」などという楽観は、サービスを公開した瞬間に砕け散ってしまいます。後々面倒なことになるのが簡単に予想できてしまったので、ここで手を抜くわけにはいきませんでした。
開発を始めた当初は、モデレーションにここまで時間がかかるとは思っていませんでした。
質問の送受信、MiAuth、MFMレンダリングといったガワの機能は、やるべきことが明確なので実装も比較的スムーズに進みます。しかし、モデレーションは何を防ぐべきか、どこまで防ぐべきか、防いだ結果として正常な利用を阻害していないかという判断の連続で、技術的な難しさよりも設計上の判断の多さに消耗しました。
## コンテンツフィルタリング
質問のフィルタは2層構造で実装しています。
### NGワード
各ユーザが自分で設定できるNGワードフィルタです。単純な文字列マッチだけでなく、正規表現にも対応しています。ただし、ユーザが入力する正規表現をそのままnew RegExp()に突っ込むわけにはいきません。ReDoSの対策が必要です。
悪意がなくても、正規表現に不慣れなユーザが壊滅的にパフォーマンスの悪いパターンを入力してしまうことは十分にあり得ます。Cloudflare Workersには厳しいCPU Time Limitがあるため、一つの正規表現マッチングでWorkerが死ぬのは避けなければなりません。
function checkNgWords(content: string, ngWords: NgWord[]): boolean {
const normalizedContent = normalizeForNgCheck(content);
const normalizedContentLower = normalizedContent.toLowerCase();
for (const ngWord of ngWords) {
const normalizedPattern = normalizeForNgCheck(ngWord.pattern);
if (!normalizedPattern) continue;
// ざっくりReDoS対策
if (normalizedPattern.length > 200) continue;
if (ngWord.isRegex) {
// 安全でない正規表現はリテラルマッチにフォールバック
if (!isSafeRegexPattern(normalizedPattern)) {
if (normalizedContentLower.includes(normalizedPattern.toLowerCase())) return true;
continue;
}
if (new RegExp(normalizedPattern, 'i').test(normalizedContent)) return true;
} else {
if (normalizedContentLower.includes(normalizedPattern.toLowerCase())) return true;
}
}
return false;
}まず、パターンの長さが200文字を超える場合は問答無用でスキップします。次に、パターンの安全性を検証し、危険と判定された場合はリテラルマッチにフォールバックします。
正規表現としての解釈を諦める代わりに、少なくとも文字列としてのマッチは試みるという、可用性重視の設計です。正規表現が使えなくても、テキストに含まれているかどうかのチェックはできるのでよしとしています。
また、入力テキストとパターンの双方にNFKC正規化とゼロ幅文字の除去を適用しています。
これがないと、見た目が同じでもバイト列が異なる文字列でフィルタをすり抜けられてしまいます。ゼロ幅文字を挟んで単語を分断するという手口も、この正規化で潰しています。
こういった回避手法は割といくらでも思いつくものあって、正直イタチごっこ感は否めません。
### OpenAI Moderation API
ユーザが有効にしている場合のみ、OpenAI Moderation APIで有害コンテンツを検出します。このAPIを採用した理由は非常にシンプルで、無料だからです。何度叩いても課金が発生しません。すごくありがたい。
hate, harassment, self-harm, sexual, violenceなど11カテゴリの判定に対応しており、カテゴリ別のカスタム閾値も設定できるようにしました。
というのも、OpenAI Moderation APIがデフォルトで返すboolean判定は、正直なところ微妙な精度です。閾値が固定であるため、カジュアルな表現を過剰にブロックしてしまったり、逆に明らかに有害なコンテンツを見逃したりすることがあります。
そこで、APIが返すスコアに対してユーザ自身がカテゴリ別の許容ラインを調整できるようにしています。
また、設計思想として、モデレーション全体を通じて可用性を最優先にしています。OpenAI APIが落ちていたり、レートリミットに達した場合は、投稿をブロックせず通します。匿名質問箱のモデレーションAPIが障害を起こしているからといって質問が一切送れなくなるのは本末転倒ですし、モデレーションはあくまで補助的な防衛線であって、サービスのコア機能を止めてまで守るべきものではありません。
リトライは最大2回、指数バックオフで行い、429の場合はRetry-Afterヘッダを尊重します。全ての結果はDBに記録し、質問のPKとの紐付けも行っているため、後から監査トレイルとして追跡可能です。
## レートリミットと重複検出
レートリミットはKVベースのスライディングウィンドウ方式で実装しています。
export async function checkRateLimit(
kv: KVNamespace | null,
action: string,
identifier: string,
options: RateLimitOptions,
): Promise<RateLimitResult> {
if (!kv) {
return { allowed: true, remaining: options.maxRequests - 1, retryAfterSeconds: 0 };
}
const key = `${KV_PREFIX}${action}:${identifier}`;
const entry = await kv.get(key, { type: 'json' });
const validTimestamps = entry.timestamps.filter(t => now - t < options.windowMs);
if (validTimestamps.length >= options.maxRequests) {
return { allowed: false, remaining: 0, retryAfterSeconds: ... };
}
return { allowed: true, remaining: options.maxRequests - validTimestamps.length - 1, retryAfterSeconds: 0 };
}
IPアドレスごとに1分間5回までの制限をかけています。加えて、直近20件のコンテンツハッシュを保持し、同一IPからの重複投稿を検出します。ハッシュはtrim・lowercase・スペース正規化した上で簡易ハッシュを取っているため、微妙な表記揺れ程度では重複として弾かれません。完全に同じ内容の連続投稿を防ぐのが目的です。CG-NAT配下のグローバルなアドレスを独占しないデバイス等からの書き込みも想定できますが、まず同一の書き込みを行うことはないでしょうし、多分これで問題ないかと思っています。
また、KVは結果整合のためisolate間でわずかなタイムラグがあります。完璧なレートリミットにはなりませんが、in-memoryのMapだとisolateが分離されているWorkers環境では全く機能しないため、KVを使うのが現実的な落とし所だと考えました。
もしKVへの接続が失敗した場合はリクエストを許可する方向に倒し、レートリミットの記録に失敗してもエラーは無視します。レートリミットが一時的に効かなくなることと、サービス自体が利用不能になることを比較すれば無難な選択をしていると思います。
## 質問の破棄
こうしたフィルタで不正な投稿をブロックした場合の処理にも、ひと工夫入れています。具体的には、ブロックした事実を攻撃者に伝えないよう、エラーレスポンスは返さず、あたかも質問が正常に送信されたかのような成功レスポンスを返すようにしました。
if (ngWords.length > 0 && checkNgWords(body.content, ngWords)) {
return {
question: {
id: 'hogehogefugafuga',
recipientId: body.recipientId,
content: body.content,
isAnonymous: body.isAnonymous ?? false,
createdAt: new Date().toISOString(),
},
};
}
ここの実装で少し悩んだのは、悪意のないユーザがNGワードに引っかかった場合のことです。
自分の質問が届いていないことに気づかない、という体験は決して良いものではありません。しかし、NGワードを公開してしまえばフィルタとして機能しなくなりますし、質問がブロックされたことを明示すればどの単語がNGなのかを推測される可能性があります。
結局、セキュリティと利便性のトレードオフとして、ユーザに見えない形で自動的に破棄することにしました。
これが一番無難なのかなと思っています。
# Internationalization
公開後、改修・機能追加を進める中でフロントエンドの課題として浮上したのが多言語対応です。
現状、Mewkは日本語・英語・韓国語の3言語に対応しています。各言語のロケールファイルはそれぞれ15万文字前後のTypeScriptオブジェクトで、エラーメッセージ、UIラベル、通知テキスト、設定画面の説明文に至るまで、全ての文言を網羅しています。
正直なところ、多言語対応は当初の要件には入っていませんでした。しかし、Misskeyのユーザ層を考えると、日本語だけでは拾いきれない潜在的なユーザがかなりいます。特に韓国語圏のMisskeyコミュニティは活発で、対応しない手はありませんでした。
この翻訳作業にClaude Codeが非常に役立ちました。日本語のファイルを渡して「これを英語に翻訳して」「これを韓国語に翻訳して」と指示するだけで、文脈を理解した上でかなりの精度で翻訳してくれます。技術用語の扱いや、UIにおける文字数の感覚も概ね適切でした。もしこれを人力で全てやっていたら、それだけで数日は余計にかかっていたでしょう。
実際、手動での確認も含め、2日程度で完成しています。すごいですね。
数ヶ月前まで、LLMにコードを書かせるなんてとんでもないと割と本気で思っていました。
いつぞやの記事では、LLMは確率的に嘘をつくことしかできない残念な存在だと書きましたし、その認識は本質的には今も変わっていません。ただ、実際に使ってみると、翻訳やボイラープレートの生成、リファクタリングの提案といった、ある程度パターンが決まった作業においては驚くほど有用です。
とはいえ、放置するととんでもない実装をすることがあります。
勝手にエラーハンドリングを追加したり、聞いてもいない最適化を施したり、存在しないAPIを自信満々に呼び出したり。「ドキュメントに書いてあることだけをやってね」と明確に指示しないと、暴走が始まります。結局のところ、LLMが吐き出したコードを正しく評価し、取捨選択できるだけの知識と勘所がなければ、道具として使いこなすことはできないのでしょう。
コードが書けない人間がLLMでコードを書ける時代が来た、みたいな言説は相変わらずナンセンスだと思います。
LLMは優秀な手下ではありますが、それを使いこなすためには、吐かれた成果物を評価できるだけの能力が使う側に求められます。
LLMによって開発者の仕事がなくなるのではなく、開発者がLLMを使うことでより多くのことを、より速くできるようになる。それだけの話です。
職を失うことは当面なさそうで残念です。
# さいごに
開発開始から2週間で公開できたとはいえ、体感としては思ったより時間がかかりました。
いや、2週間で公開しているのだから客観的には速い方なのでしょうが、開発中は「こんなに時間がかかるはずじゃなかった」という感覚が常につきまとっていました。
質問の送受信、MiAuth認証、MFMレンダリングといった主要機能の実装自体はそこまで複雑ではなかったのですが、それ以外のあまり目立たない機能の実装が、開発時間の大部分を占めました。機能を作ることよりも、その機能が悪用されないようにすることの方が難しい。これはサービス開発における普遍的な教訓なのだと思います。
ありがたいことに、リリースから1ヶ月少々が経過した現在、約2,000人ものユーザにご登録いただき、日々たくさんの質問が飛び交っています。
直近では、ユーザから「MFMが使える質問箱が欲しかった」「新着質問の通知がMisskeyへ届いて嬉しい」、「韓国語に対応していてありがたい」といったフィードバックをいただいており、苦労が報われたような気がします。
自分が不便だから、自分が欲しいから作ったサービスが、結果的にこれほど多くの方に役立てているのだとすれば、開発者としてこれ以上の喜びはありません。
まだまだ細かい改善点や追加したい機能は山積みですが、引き続きモダンなエコシステムの恩恵を最大限に享受しながら、運用と開発を続けていこうと思います。
最後になりますが、Mewkの顔である可愛いロゴデザインや、プロダクト全体の色彩設計はしなもんさんにやってもらいました。本当に大感謝です🙏🏻
長い駄文にお付き合いいただき、ありがとうございました。
それでは。